一、metapath2vec [2017]
《metapath2vec: Scalable Representation Learning for Heterogeneous Networks》
基于神经网络的模型可以表达潜在
embedding,这些embedding可以捕获跨各种模式(如图像、音频、语言)的丰富、复杂数据的内部关系。社交网络 (social network)和信息网络 (information network)同样是丰富、复杂的数据,它们对人类交互(human interaction)的动态性 (dynamic)和类型(type)进行编码,并且同样适用于使用神经网络的representation learning。具体而言,通过将人们选择好友和保持联系的方式映射为social language,我们可以将NLP的最新进展自然地应用于network representation learning,尤其是著名的NLP模型word2vec。最近的一些研究提出了word2vec-based network representation learning框架,例如DeepWalk、LINE、node2vec。这些representation learning方法不是手工设计的网络特征,而是能够从raw network中自动发现有用的、且有意义的latent特征。然而,到目前为止,这些工作都集中在同质网络(
homogeneous network)(只有单一类型的节点、单一类型的关系)的representation learning上。但是,大量的社交网络和信息网络本质上是异质(heterogeneous)的,涉及多种类型的节点、以及多种类型的关系。这些异质网络(heterogeneous network)提出了独特的挑战,而这些挑战是专门为同质网络设计的representation learning模型所无法处理的。以异质学术网络(heterogeneous academic network)为例:我们如何在作者(author)、论文(paper)、会议 (venue)、组织(organization)等多种类型的节点之间有效地保留word-context概念?随机游走(如DeepWalk和node2vec中所使用的的)能否可以应用于多种类型节点的网络?我们可以直接将面向同质网络的embedding架构(如skip-gram)应用于异质网络吗?通过解决这些挑战,
latent heterogeneous network embedding可以进一步应用于各种网络挖掘任务,如节点分类、节点聚类、相似节点搜索。与传统的meta-path-based方法相比,潜在空间representation learning的优势在于它能够在没有connected meta-path的情况下对节点之间的相似性进行建模。例如,如果两个author从未在同一个venue上发表过论文(假设一个人在NIPS上发表了10篇论文,另一个人在ICML上发表了10篇论文),则他们基于APCPA的Path-Sim相似度将为零。 但是,通过network representation learning可以自然地克服相似度为零这一缺点。论文
《metapath2vec: Scalable Representation Learning for Heterogeneous Networks》形式化了异质网络representation learning问题,其目标是同时学习多种类型节点的低维潜在的embedding。论文介绍了metapath2vec框架及其扩展metapath2vec++框架。metapath2vec的目标是最大化同时保留给定异质网络的结构(structure)和语义(semantic) 的可能性。在metapath2vec中,论文首先提出了异质网络中meta-path based随机游走,从而针对各种类型的节点生成具有网络语义 (network semantic)的异质邻域(heterogeneous neighborhood)。其次,论文扩展了skip-gram模型从而促进空间临近(geographically close)节点和语义临近 (semantically close)节点的建模。最后,论文开发了一种基于异质负采样(heterogeneous negative sampling)的方法,称作metapath2vec++,可以准确有效地预测节点的异质邻域。论文提出的
metapath2vec和metapath2vec++模型不同于传统的network embedding模型,后者专注于同质网络。具体而言,传统模型对不同类型的节点和不同类型的关系进行相同的处理,导致异质节点无法产生可区分的representation,正如论文在实验中所证明的那样。此外,metapath2vec和metapath2vec++模型在几个方面也与Predictive Text Embedding: PTE模型不同。首先,
PTE是一种半监督学习模型,它结合了文本数据的label信息。其次,
PTE中的异质性来自于text network,其中包含word-word链接、word-document链接、word-label链接。本质上,PTE的原始输入是单词,输出是每个单词的embedding,因此PTE并不是多种类型的对象。
论文在下表中总结了这些方法的差异,其中列出了算法的输入,以及
《Pathsim: Meta path-based top-k similarity search in heterogeneous information networks》中使用的相同两个query在DBIS网络的top 5相似搜索结果(每一列是一个query的结果)。通过对异质邻域建模并进一步利用异质负采样技术,metapath2vec++能够为两种类型的query实现最佳的top 5相似结果。
下图展示了
16个CS会议和每个领域的相应知名学者学到的embedding(128维)的2D投影(基于PCA)可视化。值得注意的是,论文发现metapath2vec++能够自动组织这两种类型的节点并隐式学习它们之间的内部关系,这由链接每个pair的箭头的相似方向和距离所展示。例如,metapath2vec++学习J. Dean -> OSDI以及C. D. Manning -> ACL。metapath2vec也能够将每个author-conference pair紧密分组,例如R. E. Tarjan和FOCS。所有这些属性都无法从传统的network embedding模型中发现。
总而言之,论文工作的贡献如下:
形式化异质网络
representation learning的问题,并确定由网络异质性带来的独特挑战。开发有效(
effective) 的、高效(efficient) 的network embedding框架metapath2vec & metapath2vec++,用于同时保留异质网络的结构相关性(structural correlation)和语义相关性(semantic correlation)。通过广泛的实验,证明了论文提出的方法在各种异质网络挖掘任务中的有效性和可扩展性,例如节点分类(相对于
baseline提升35% ~ 219%)和节点聚类(相对于baseline提升13% ~ 16%)。演示了
metapath2vec & metapath2vec++自动发现异质网络中不同节点之间的内部语义关系,而这种关系现有工作无法发现。
相关工作:
network representation learning可以追溯到使用潜在因子模型进行网络分析和图挖掘任务,例如factorization model在推荐系统、节点分类(node classification)、关系挖掘(relational mining) 、角色发现(role discovery)中的应用。这一丰富的研究领域侧重于分解网络的matrix/tensor格式(例如,邻接矩阵),从而为网络中的节点或边生成潜在特征。然而,分解大型matrix/tensor的计算成本通常非常昂贵,并且还存在性能缺陷,这使得它对于解决大型网络中的任务既不实用、也不有效。随着深度学习技术的出现,人们致力于设计基于神经网络的
representation learning模型。例如Mikolov等人提出了word2vec框架(一个两层神经网络)来学习自然语言中word的分布式representation。DeepWalk在word2vec的基础之上提出,节点的context可以通过它们在随机游走路径中的共现 (co-occurrence) 来表示。形式上,DeepWalk将随机游走walker放在网络上从而记录walker的游走路径,其中每条随机游走路径都由一系列节点组成。这些随机游走路径可以被视为文本语料库中的sentence。最近,为了使节点的邻域多样化,Node2Vec提出了有偏随机游走walker(一种广度优先breadth-first和宽度优先width-first混合的搜索过程),从而在网络上产生节点路径。随着节点路径的生成,这两项工作都利用word2vec中的skip-gram架构来对路径中节点之间的结构相关性进行建模。此外,人们已经提出了几种其它方法来学习网络中的
representation。特别地,为了学习network embedding,LINE将节点的context分解为一阶邻近性(friend关系)、二阶邻近性(friend’ friend关系),这进一步发展为用于嵌入文本数据的半监督模型PTE。我们的工作通过设计
metapath2vec和metapath2vec++模型来进一步研究这个方向,从而捕获具有多种类型节点的大型异质网络所表现出的结构相关性和语义相关性。这是以前的模型所无法处理的,并且我们将这些模型应用于各种网络挖掘任务。
1.1 模型
1.1.1 问题定义
异质网络(
Heterogeneous Network)定义:异质网络是一个图其中
例如可以用作者(
author:A)、论文(paper:P)、会议 (venue:V)、组织(organization:O)作为节点类型来表示下图中的学术网络(academic network)。其中边可以表示合作者关系(coauthor)A-A、发表关系(publish)A-P,P-V、附属关系(affiliation)O-A,引用关系(reference)P-P。黄色虚线表示coauthor关系,红色虚线表示引用关系。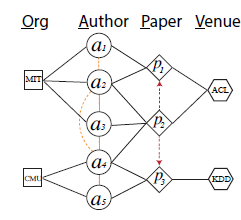
异质网络
representation learning问题:给定一个异质网络latent representationrepresentation能够捕获网络的结构关系以及语义关系。任务的输出是一个低维矩阵embedding。注意,尽管
embedding都被映射到相同的潜在空间中。学到的节点embedding可以应用于各种异质网络挖掘任务,如节点分类、节点聚类、相似节点搜索等。问题的挑战来自于网络异质性,其中很难直接应用同质的
language embedding方法和同质的network embedding方法。network embedding模型的基本假设是:在embedding空间保持节点及其邻域(上下文context)之间的邻近性。但是在异质网络中,如何定义和建模node–neighborhood的概念?另外,我们如何优化embedding模型,其中该模型有效维护多种类型节点和关系的结构和语义?
1.1.2 metapath2vec
我们提出了一个通用框架
metapath2vec,从而在异质网络中学习所需要的的node representation。metapath2vec的目标是在考虑多种类型的节点和边的情况下最大化网络概率network probability。同质的
network embedding:首先考虑word2vec模型及其在同质network embedding任务中的应用。给定一个文本语料库,Mikolov等人提出word2vec来学习语料库中单词的分布式representation。受此启发,DeepWalk和node2vec旨在将文本语料库中的word-context概念映射到network中。这两种方法都利用随机游走来实现这一点,并利用skip-gram模型来学习node representation,这有助于在同质网络中预测节点的结构上下文(structural context)(即局部邻域local neighborhood)。通常,给定网络local structure)来最大化网络概率:其中:
为了对顶点的异质邻域建模,
metapath2vec引入了异质skip-gram模型Heterogeneous Skip-Gram。为了将异质网络结构融合到异质skip-gram模型中,metapath2vec引入了基于meta-path的随机游走。异质
skip-gram模型:在metapath2vec中,给定异质网络skip-gram能够学习异质网络node representation:softmax函数定义:其中:
embedding向量;embedding向量。注意:
这里
node embedding和context embedding都是在同一个embedding空间中,它们共享embedding矩阵由于
pairDeepWalk的目标函数。因此metapath2vec的目标函数和metapath2vec的目标函数是相同的,而且区别在于随机游走的方式不同。
author节点author邻域venue邻域organization邻域paper邻域为了有效优化目标函数,
Milkolov等人引入了负采样,它从网络种随机采样相对较小的一组节点来代替softmax。metapath2vec也采用了相同的负采样技术。给定一个负采样大小其中:
sigmoid函数。metapath2vec无视节点类型来构建节点的频率分布frequency distribution。
基于
meta-path的随机游走:如何有效的将网络结构转化为skip-gram?在DeepWalk和node2vec中,这是通过将random walker在网络上结合一个邻域函数来遍历的节点路径来实现的。我们也可以将
random walker放到异质网络中,从而生成多种类型节点的路径。在随机游走的第node2vec和DeepWalk的输入。但是,《Pathsim: Meta path-based top-k similarity search in heterogeneous information networks》证明了:异质随机游走偏向于高度可见的节点类型(即那些在路径中频繁出现的节点类型),以及中心节点(即那些出现频繁出现在关键路径中的节点)。有鉴于此,我们设计了基于meta-path的随机游走,从而生成能够捕获不同类型节点之间语义相关性和结构相关性的随机游走序列,从而有助于我们将异质网络结构转化为异质skip-gram。形式化地,一个
meta-path范式其中:
以下图为例:
meta-path: APA代表两个author(类型为A) 在同一论文(类型为P) 上的co-author关系,meta-path: APVPA代表两个author(类型为A)在同一个会议(类型为V)的不同论文(类型为P)上的co-venue关系。先前的工作表明:异质信息网络中的许多数据挖掘任务都可以通过
meta-path建模受益。这里我们展示如何利用meta-path来指导异质random walker。给定一个异质网络meta-path范式其中:
即,下一个节点仅在类型为
由于
random walker必须根据预定义的meta-pathmeta-path都是对称的,如基于
meta-path的随机游走策略可以确保不同类型节点之间的语义关系可以正确的合并到skip-gram中。如下图所示,假设上一个节点为CMU,当前节点为meta-path的范式OAPVPAO下,下一个节点倾向于论文类型的节点P),从而保持路径的语义。总体而言,
metapath2vec和node2vec都是在DeepWalk基础上针对随机游走策略的改进。
1.1.3 metapath2vec ++
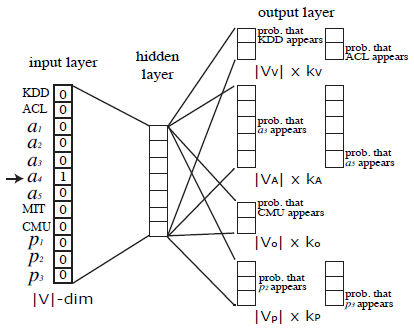
metapath2vec在创建点softmax函数中的节点类型信息。即:在给定节点metapath2vec实际上采用了所有类型的负样本,包括相同类型异质负采样(
heterogeneous negative sampling):我们进一步提出metapath2vec++框架,其中softmax根据上下文其中
这样做时,
metapath2vec++为skip-gram模型输出层中的每种邻域类型定义一组softmax分布。回想一下,在metapath2vec、node2vec、DeepWalk中,输出softmax分布的维度等于网络的节点数量metapath2vec ++中,输出softmax分布的维度由类型为metapath2vec ++输出四组softmax分布,每一组分布对应于不同的邻域节点类型:会议V、作者A、组织O、论文P。注意,这里对每种类型顶点指定各自不同的窗口大小。
受到
PTE的启发,metapath2vec在负采样过程中同样可以根据邻居节点其中
上式的物理意义为:负采样仅在上下文
目标函数的梯度为:
其中
最终可以通过随机梯度下降算法来对模型进行优化求解。
metapath2vec++算法:输入:
异构网络
一个
meta-path范式每个顶点开始的游走序列的数量
每条游走序列的长度
embedding维度邻域大小
输出:顶点的
embedding矩阵算法步骤:
初始化
迭代
遍历图
返回
MetaPathRandomWalk算法:输入:
异构网络
一个
meta-path范式当前顶点
每条游走序列的长度
输出:一条
meta-path随机游走序列算法步骤:
初始化:
迭代
根据
返回
HeterogeneousSkipGram算法:输入:
当前的
邻域大小
随机游走序列
输出:更新后的
算法步骤:
迭代
取出当前顶点
其中
下图给出了异质学术网络
heterogeneous academic network,以及学习该网络embedding的metapath2vec/metapath2vec ++的skip-gram架构。图
a的黄色虚线表示co-author关系,红色虚线表示论文引用关系。图
b表示metapath2vec在预测skip-gram架构。其中图
c表示metapath2vec ++在预测skip-gram架构。metapath2vec++中使用异质skip-gram。在输出层中,它不是为邻域中所有类型的节点指定一组多项式分布,而是为邻域中每种类型的节点指定各自的一组多项式分布。
注:我们可以指定多个
metapath,针对每个metapath学到对应的embedding,最后将所有embedding聚合起来从而进行metapath ensemble。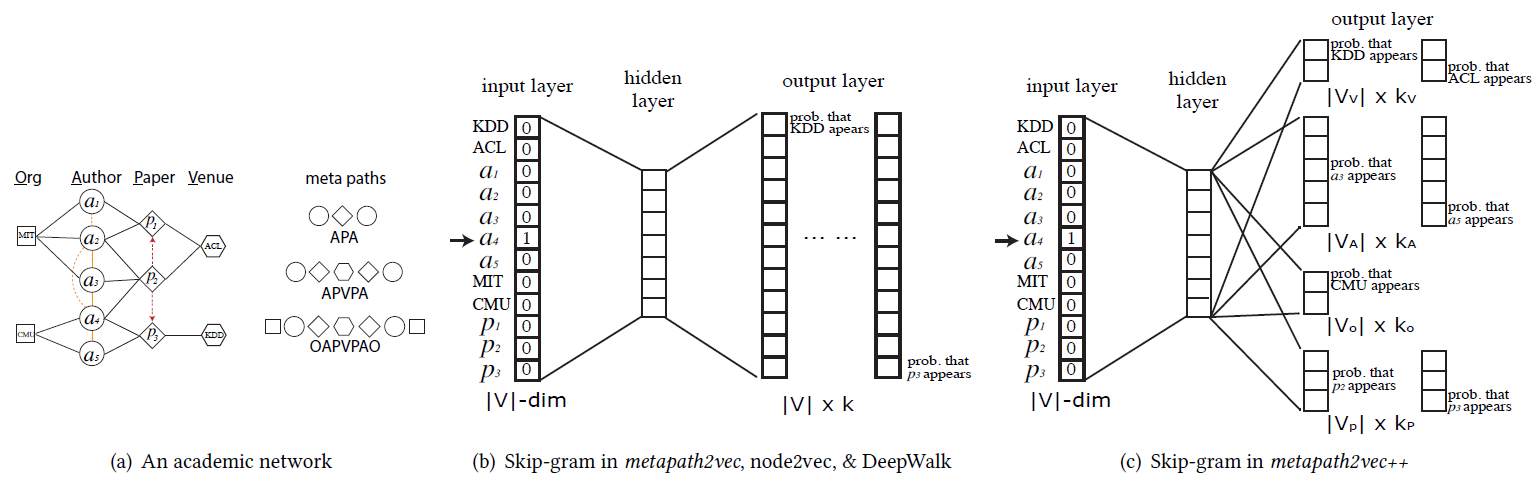
未来方向:
metapath2vec/metapath2vec++模型和DeepWalk/node2vec一样,在对网络采样生成大量随机游走路径时,面临大量中间临时输出数据的挑战。因此识别和优化采样空间是一个重要方向。和所有基于
meta-path异质网络挖掘方法一样,可以通过自动学习有意义的meta-path来进一步改善metapath2vec/metapath2vec++。扩展模型从而融合演变中的异质网络的动态性
dynamic。将模型泛化到不同风格
genre的异质网络。
1.2 实验
这里我们展示了
metapath2vec/metapath2vec ++用于异质网络representation learning的效果和效率。我们评估了经典的三种异质网络挖掘任务,包括:节点分类问题、节点聚类问题、相似节点搜索问题。另外,我们还通过
tensorflow的embedding可视化来观察异质学术网络中学到的节点embedding。数据集:我们使用以下两个异质网络,它们都是公开的:
AMiner Computer Science(CS) dataset:包含2016年之前j举行的3883个计算机科学venue(包含会议conference和期刊journal)的9323739名计算机科学家,以及3194405篇论文。我们构建了一个异质网络,该网络包含三种类型的节点:author:A、paper:P、venue:V。不同类型节点之间的链接代表不同的关系。Database and Information Systems(DBIS) dataset:包含464个会议,以及其中top-5000个作者,以及对应的72902篇论文。我们也构建了一个异质网络,该网络包含三种类型的节点:author:A、paper:P、venue:V。
baseline方法:我们将metapath2vec/metapath2vec ++和以下几种最近的网络representation learning方法进行比较:DeepWalk/node2vec:在相同的随机游走序列输入下,我们发现DeepWalk的hierarchical softmax和node2vec的负采样之间并未产生显著差异,因此我们这里采用node2vec。LINE:我们使用同时采用了1阶邻近性和2阶邻近性的LINE模型。PTE:我们构建了三个异质二部图A-A, A-V, V-V,并将其作为无监督embedding学习方法的约束。谱聚类(
Spectral Clustering)/图因子分解(Graph Factorization):因为早前的研究表明DeepWalk和LINE的性能超越了它们,因此这里并不考虑这两种方法。
参数配置:对于所有模型,我们使用以下相同的参数:
每个顶点开始的随机游走序列数量
每个随机游走序列长度
隐向量维度
LINE模型,其一阶embedding和 二阶embedding的维度都是128。邻域
size负采样
size对于
metapath2vec/metapath2vec ++,我们还需要指定meta-path范式来指导随机游走的生成。我们调查了大多数基于meta-path的工作,发现异质学术网络中最常用和有效的meta-path范式是APA和APVPA。注意,APA表示co-author语义,即传统同质网络的collaboration关系;APVPA代表两个author在同一个venue发表了论文(可以是不同的论文)的异质语义。我们的实验表明:meta-path范式APVPA产生的节点embedding可以泛化到各种异质学术网络的挖掘任务中。
最后,在参数敏感性实验中,我们对参数中的一个进行变化,同时固定其它参数来观察
metapath2vec/metapath2vec ++的效果。
1.2.1 节点分类
我们使用第三方的
label来确定每个顶点的类别。首先将
Google Scholar中的八个会议的研究类别与AMiner数据中的会议进行匹配:Computational Linguistics, Computer Graphics, Computer Networks & Wireless Communication, Computer Vision & Pattern Recognition, Computing Systems, Databases & Information Systems, Human Computer Interaction, Theoretical Computer Science每种类别
20个会议。在这160个会议中,有133个已经成功匹配并进行相应的标记。每篇论文标记为它所属会议的类别。然后,对于这
133个会议的论文的每位作者,将他/她分配给他/她大部分论文的类别,如果论文类别分布均匀则随机选择一个类别。最终有246678位作者标记了研究类别。
我们从完整的
AMiner数据集中学到节点的embedding,然后将上述节点标记以及对应的节点embedding一起作为逻辑回归分类器的输入。我们将训练集规模从标记样本的
5%逐渐增加到90%,并使用剩下顶点进行测试。我们将每个实验重复十轮,并报告平均的macro-F1和micro-F1。下表给出了
Venue类型顶点的分类结果。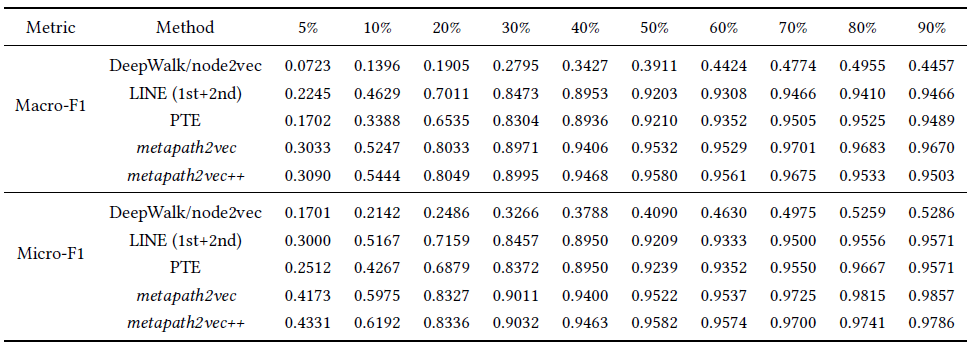
下表给出了
Author类型顶点的分类结果:
结论:
metapath2ve/metapath2vec ++模型始终一致且明显的优于所有其它基准方法。在预测
Venue类型节点的类别时,在训练数据量较小的情况下,metapath2vec/metapath2vec ++的优势特别明显。例如,给定5%的节点作为训练集,相对于DeepWalk/node2vec, LINE, PTE,metapath2vec/metapath2vec++在Macro-F1方面实现了0.08 ~ 0.23的绝对提升(相对提升35% ~ 319%),在Micro-F1方面实现了0.13 ~ 0.26的绝对提升(相对提升39% ~ 145%)。在预测
Author类型节点的类别时,每种方法的性能在不同训练集规模情况下都相对稳定metapath2vec/metapath2vec ++相对LINE和PTE稳定提升2% ~ 3%、比DeepWalk/node2vec稳定提升~20%。
总之,通过多分类性能评估,
metapath2vec/metapath2vec++学到的异质node embedding比当前SOTA的方法要好得多。metapath2vec/metapath2vec++方法的优势在于它们对网络异质性挑战(包含多种类型节点和多种类型边)的适当考虑和适应。我们接下来对
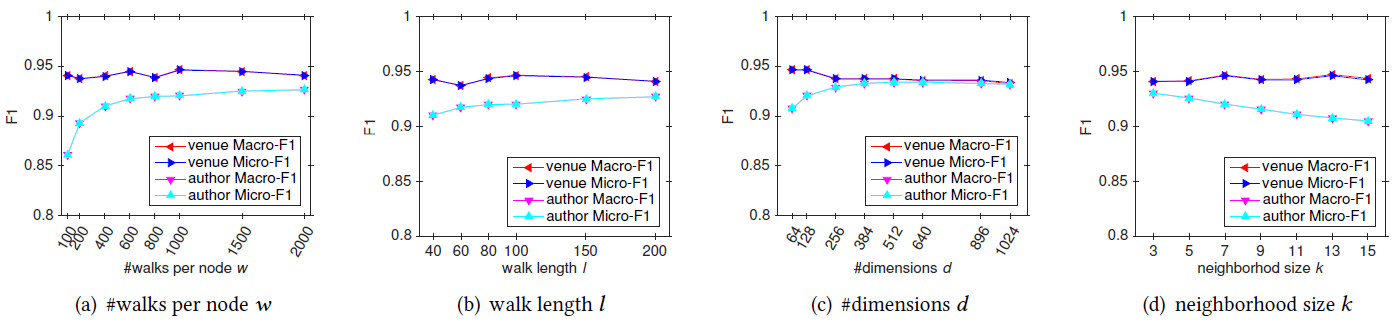
metapath2vec ++的几个通用参数进行超参数敏感性分析。我们变化其中的一个超参数,然后固定其它的超参数。结论:
从图
a和b可以看到,参数author节点的分类性能是正向的,其中author节点分类性能提到到峰值附近。但是令人惊讶的是,
venue节点的分类性能无关。从图
c和d可以看到,embedding尺寸venue节点分类性能无关。而author节点分类性能至关重要,下降的曲线表明较小的邻域大小对于author节点能够产生更好的embedding表示。这和同质图完全不同。在同质图中,邻域大小根据分析,
metapath2vec++对这些参数并不严格敏感,并且能够在cost-effective超参数选择的条件下(选择范围越小则效率越高)达到高性能。此外,我们的结果还表明,这些通用的超参数在异质网络中表示出和同质网络中不同的效果,这表明对于异质网络representation learning需要采用不同的思路和解决方案。
1.2.2 节点聚类
我们采用与上述分类任务中使用的相同的八个类别的
author节点和venue节点(AMiner CS数据集),我们针对这些节点的embedding进行聚类。这里我们使用k-means聚类算法,并通过归一化的互信息NMI来评估聚类效果。给定随机变量
所有聚类实验均进行十次,并报告平均性能,结果如下表所示。结论:
总体而言,
metapath2vec和metapath2vec ++优于其它所有方法。从
venue节点聚合结果可以看到,大多数方法(除了DeepWalk/node2vec)的NMI都较高,因此该任务相对容易。但是我们的方法比LINE和PTE高2% ~ 3%。author节点聚类指标都偏低,因此任务更难。但是我们的方法相比最佳baseline(LINE和PTE)上获得更显著的增益:大约提升13% ~ 16%。
总之,和
baseline相比,metapath2vec和metapath2vec ++为网络中不同类型的节点生成了更合适的embedding,这表明它们能够捕获和整合异质网络中各种类型节点之间的底层结构关系和语义关系。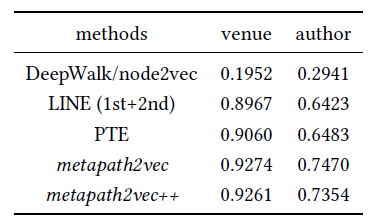
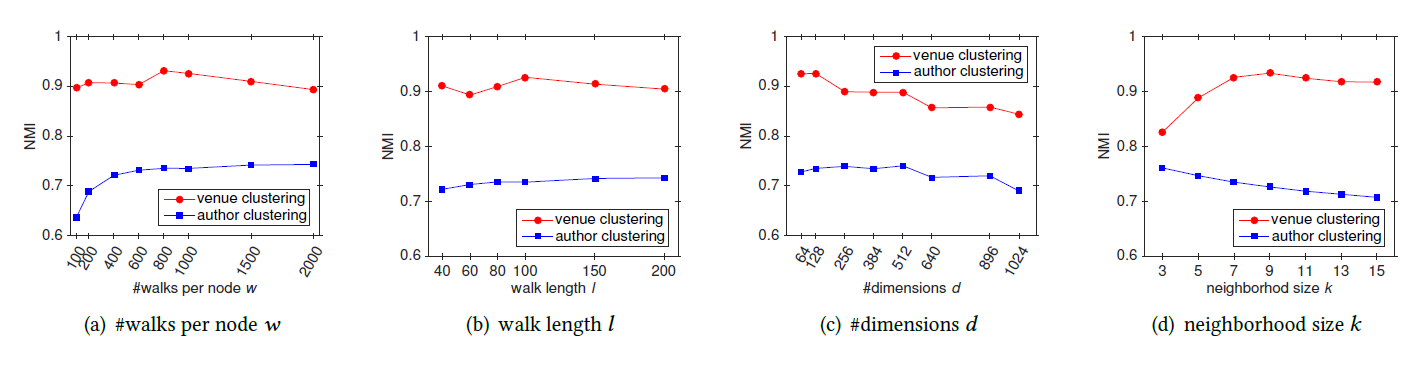
和分类实验的步骤相同,我们研究了聚类任务中
metapath2vec ++的参数敏感性,衡量指标为NMI。从图
a和b可以看到,author节点和venue节点在author节点的聚类结构正向影响,但是对venue节点影响不大。从图
c和d可以看到,对于author节点,venue节点,NMI先增加后减小。所有这些意味着对于
author节点和venue节点,当embedding可以得到较好的聚类结果。
11.2.3 相似节点搜索
我们从
AMiner数据集选择16个不同领域的顶级CS会议,然后通过余弦相似度选择这些会议节点的top 10相似度结果。结论:对于
query节点ACL,metapath2vec++返回的venue具有相同的主题NLP,如EMNLP(1st)、NAACL(2nd)、Computational Linguistics(3rd)、CoNLL(4th)、COLING(5th)等等。其它领域的会议的
query也有类似的结果。大多数情况下,
top3结果涵盖了和query会议声望类似的venue。例如theory理论领域的STOC和FOCS、system系统领域的OSDI和SOSP、architecture架构领域的HPCA和ISCA、security安全领域的CCS和S&P、human-computer interaction人机交互领域的CSCW和CHI、NLP领域的EMNLP和ACL、machine learning机器学习领域的ICML和NIPS、web领域的WSDM和WWW、artificial intelligence人工智能领域的AAAI和UCAI、database数据库领域的PVLDB和SIGMOD等等。
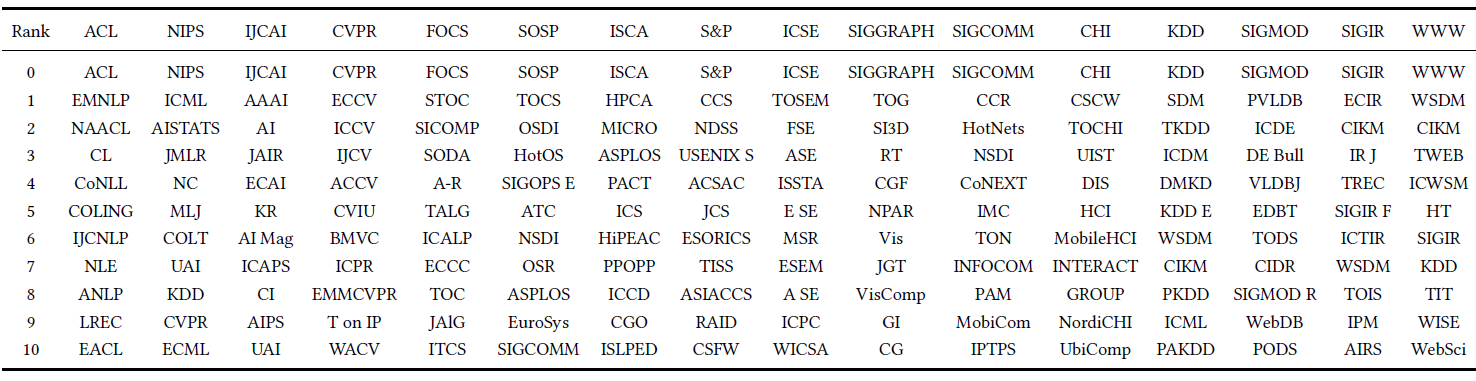
类似的,我们从
DBIS数据中选择另外的5个CS会议,然后通过余弦相似度选择这些会议节点的top 10相似度结果。结论也类似。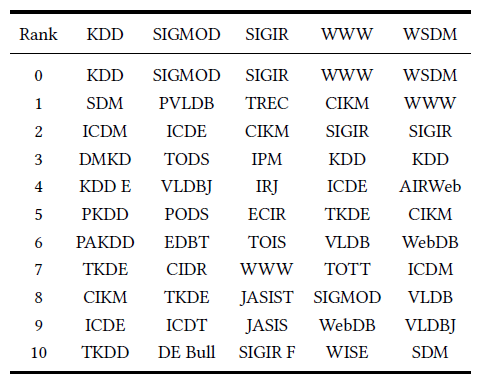
我们从
DBIS数据中选择一个会议节点、一个作者节点,然后比较不同embedding方法找出的top-5相似度的结果。结果如下表所示,其中metapath2vec ++能够针对不同类型的query节点获得最佳的top-5相似节点。
1.2.4 可视化
我们使用
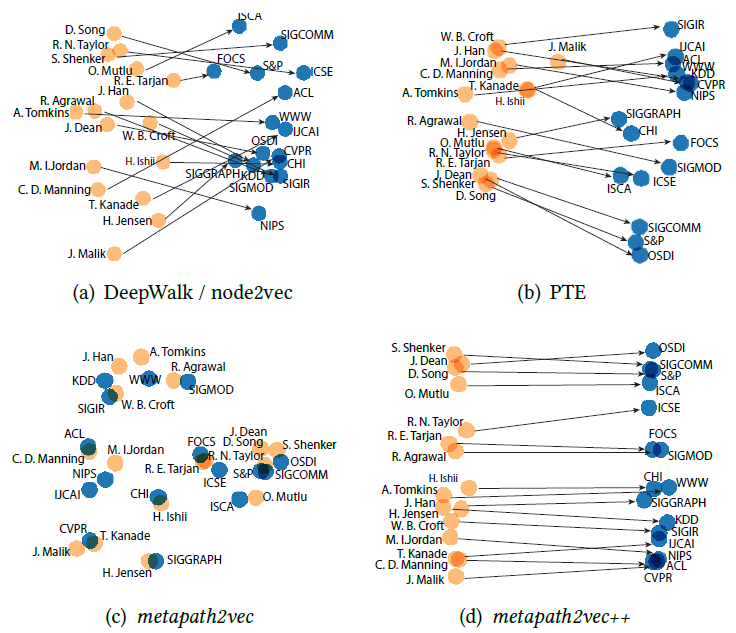
tensorflow embedding2维PCA来进一步可视化模型学到的节点embedding。我们从AMiner CS数据集选择16个不同领域的顶级CS会议,以及对应的顶级作者进行可视化。从图
d可以看到,metapath2vec++能自动组织这两种类型的节点,并隐式学习它们的内部关系。这种内部关系可以通过连接每对节点的箭头的方向和距离表示,如J.Dean --> OSDI,C.D.Manning --> ACL,R.E.Tarjan --> FOCS,M.I.Jordan --> NIPS等等。这两类节点位于两个独立的“列”中,很显然图
a和b的embedding无法达到同样的效果。从图
c可以看到,metapath2vec能够将每对author-venue pair对进行紧密的分组,而不是将两种类型的节点分类两列。如R.E.Tarjan + FOCS、H.Jensen + SIGGRAPH、H.Ishli + CHI、R.Agrawal + SIGMOD等等。 常规的embedding方法也无法达到这种效果。metapath2vec/metapath2vec++都可以将来自相似领域的节点放在一起、不同领域的节点相距较远。这种分组不仅反映在venue节点上,也反映在author节点上。
下图通过
t-SNE可视化了metapath2vec++学到的AMiner数据集不同领域的顶级CS会议,一共48个会议、16个领域,每个领域3个会议。可以看到:来自同一个领域的会议彼此聚在一起,并且不同组之间的间隔比较明显。这进一步验证了
metapath2vec++的embedding能力。另外,异质
embedding能够揭示不同领域的节点之间的相似性。如,右下角的Core CS领域的几个簇(计算机系统簇OSDI、计算机网络簇SIGCOMM、计算机安全簇S&P、计算机架构簇ISCA)、右上角的Big AI领域的几个簇(数据挖掘簇KDD、信息检索簇SIGIR、AI簇AI、机器学习簇NIPS、NLP簇ACL、计算机视觉簇CVPR)。
因此,这些可视化结果直观地展示了
metapath2vec++的新能力:发现、建模、以及捕获异质网络中多种类型节点之间的底层结构关系和语义关系。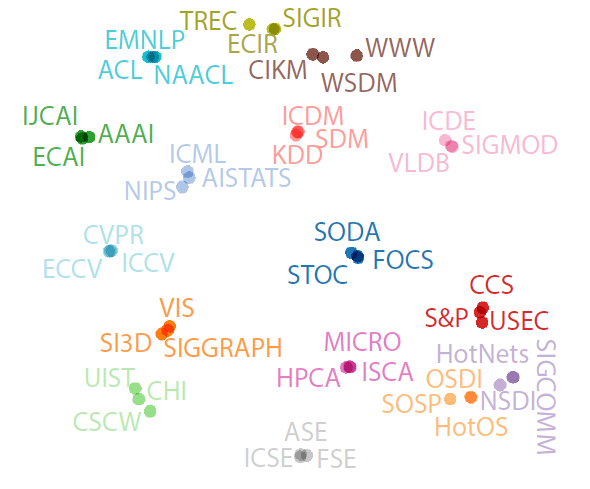
1.2.5 可扩展性
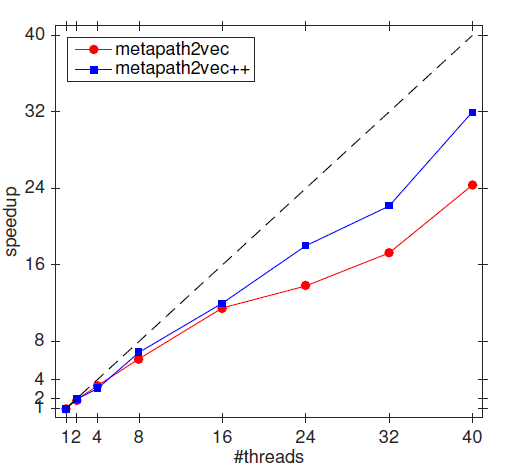
metapath2vec/metapah2vec ++可以使用和word2vec/node2vec中相同的机制来并行化。我们对AMiner数据集进行实验,实验在Quad 12(48) core 2.3 GHz Intel Xeon CPUs E7-4850上进行。我们实现不同的线程数{1,2,4,8,16,24,32,40},每个线程使用一个CPU core。下面给出了
metapath2vec/metapath2vec++的加速比。最佳加速比由虚线16个core时,它们可以实现11-12倍的加速比;使用40个core时,它们可以实现24-32倍加速比。在使用
40个core时,metapath2vec ++的学习过程只需要9分组即可训练整个AMS CS网络的embedding,该网络由900万以上的作者、3300多个venue、300万篇论文组成。总体而言,对于具有数百万个节点的大规模异质网络,metapath2vec/metapath2vec++是高效的且scalable的。